

La qualità dei dati è il fondamento di ogni progetto AI di successo. In questa guida si parlerà dei pilastri relativi al data quality management per massimizzare il potenziale dei sistemi di intelligenza artificiale.
Indice
✅ Introduzione
✅ I Fondamenti della Qualità dei Dati
✅ I 6 Pilastri del Data Quality
✅ Data quality best practices
✅ Verso un futuro guidato dalla qualità dei dati
Introduzione
Nel panorama tecnologico attuale, l’Intelligenza Artificiale sta rivoluzionando ogni settore industriale. Dalle applicazioni consumer ai sistemi enterprise, l’AI promette di automatizzare processi complessi e fornire insights preziosi. Ad esempio, da tempo si parla di agenti AI a cui delegheremo anche un certo grado di libertà nel prendere decisioni ed eseguire azioni.
In questo scenario di rapida evoluzione, emerge un elemento cruciale che spesso passa in secondo piano: la qualità dei dati.
La sua importanza diventa ancora più critica oggi, in un momento in cui le aziende hanno accesso a strumenti che permettono di addestrare facilmente agenti AI sui propri dati aziendali.
“La qualità dei dati non significa solo avere molti dati, ma avere dati adatti allo scopo” (Zeba Hasan, Google Cloud Platform)
Questa affermazione racchiude una verità fondamentale: anche il modello di AI più sofisticato fallirà, o peggio, produrrà risultati potenzialmente dannosi, se alimentato con dati di scarsa qualità.
I fondamenti della qualità dei dati
Nel contesto dell’Intelligenza Artificiale e degli agenti autonomi, è fondamentale comprendere la distinzione tra qualità dei dati e integrità dei dati. Questa distinzione diventa particolarmente rilevante quando si progettano sistemi AI che devono prendere decisioni basate su dati provenienti da fonti diverse e che necessitano di essere sia accurati che protetti.
La qualità dei dati si concentra sull’essenza stessa dell’informazione. Si occupa di garantire che ogni singolo record nel nostro dataset sia accurato e utile per lo scopo previsto. Questo significa assicurarsi che i dati riflettano fedelmente la realtà che rappresentano, attraverso processi di pulizia, standardizzazione e arricchimento. Quando addestriamo un modello di AI, la qualità dei dati determina direttamente la capacità del modello di apprendere pattern significativi e generare previsioni accurate.
L’integrità dei dati, d’altra parte, si concentra sulla preservazione e sulla consistenza dell’informazione durante tutto il suo ciclo di vita. Questo aspetto diventa cruciale quando i dati vengono utilizzati da sistemi AI distribuiti o quando vengono condivisi tra diverse componenti di un’applicazione. L’integrità viene garantita attraverso meccanismi di controllo degli accessi, crittografia e strategie di backup/recovery, assicurando che i dati rimangano inalterati e affidabili nel tempo.
Comprendere questa distinzione è essenziale per sviluppare una strategia efficace di gestione dei dati per l’AI. Mentre la qualità dei dati garantisce che stiamo alimentando i nostri modelli con informazioni accurate e significative, l’integrità dei dati assicura che queste informazioni rimangano protette e consistenti attraverso tutti i sistemi e nel tempo.
Entrambi gli aspetti sono fondamentali: un sistema AI potrebbe avere dati di alta qualità, ma senza adeguate misure di integrità, questi potrebbero essere compromessi o alterati, rendendo inutili gli sforzi fatti per garantirne la qualità.
Adesso però ci concentreremo piuttosto sugli aspetti legati alla qualità dei dati.
I 6 Pilastri del “data quality framework”
La qualità dei dati si fonda su sei pilastri fondamentali, ognuno dei quali gioca un ruolo cruciale nell’assicurare che i nostri sistemi AI possano operare con efficacia e affidabilità. Vediamo nel dettaglio ciascun pilastro e come implementarlo praticamente.
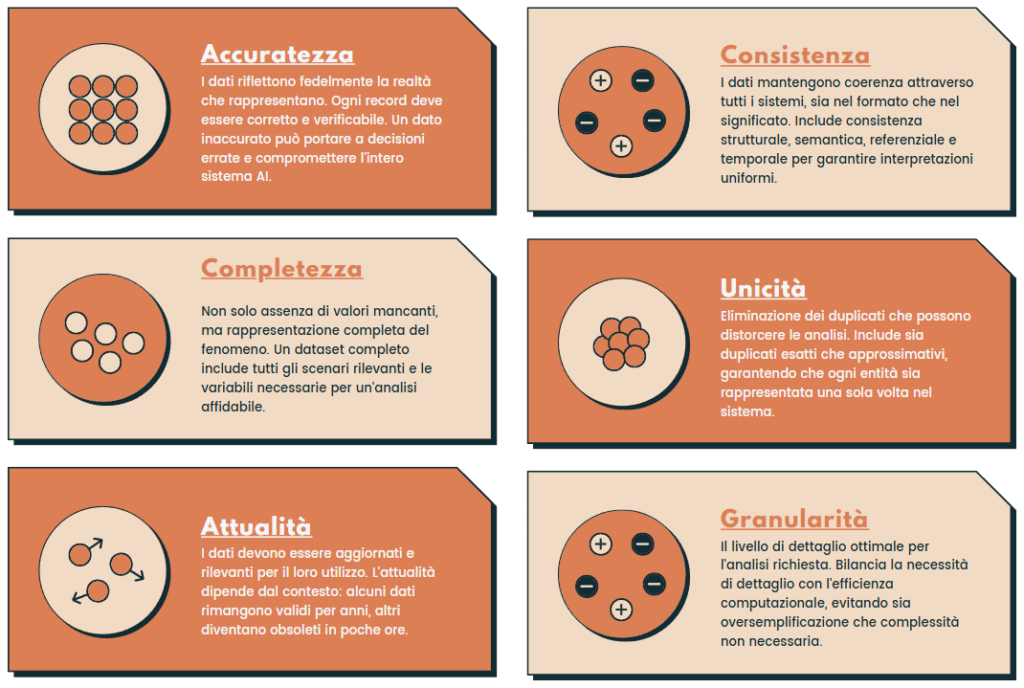
1. Accuratezza: La Base della Fiducia nei Dati
L’accuratezza è il fondamento su cui si basa ogni analisi dei dati. Un dato accurato rappresenta fedelmente la realtà che sta cercando di descrivere. Nell’era dell’AI, dove le decisioni vengono prese automaticamente sulla base dei dati, l’accuratezza diventa ancora più critica. Un errore nei dati si propaga attraverso tutto il sistema, amplificandosi potenzialmente ad ogni step del processo decisionale.
Per garantire l’accuratezza, è necessario implementare rigorosi sistemi di validazione che verifichino ogni dato in ingresso. Ecco un esempio pratico di come implementare queste validazioni:
import pandas as pd
import re
from datetime import datetime
def validate_data_accuracy(df: pd.DataFrame) -> pd.DataFrame:
"""
Valida l'accuratezza dei dati in un DataFrame e restituisce un report delle violazioni.
Args:
df: DataFrame contenente i dati da validare
Returns:
DataFrame contenente il report delle violazioni
"""
# Definiamo le regole di validazione
validations = []
# Validazione età
age_violations = df[~df['age'].between(0, 120)]
if not age_violations.empty:
validations.extend([
{'row_id': idx, 'field': 'age', 'value': row['age'],
'error': 'Age must be between 0 and 120'}
for idx, row in age_violations.iterrows()
])
# Validazione email con pandas str accessor
invalid_emails = df[~df['email'].str.match(r"[^@]+@[^@]+\.[^@]+", na=False)]
if not invalid_emails.empty:
validations.extend([
{'row_id': idx, 'field': 'email', 'value': row['email'],
'error': 'Invalid email format'}
for idx, row in invalid_emails.iterrows()
])
# Validazione telefono
invalid_phones = df[~df['phone'].str.match(r"^\+?1?\d{9,15}$", na=False)]
if not invalid_phones.empty:
validations.extend([
{'row_id': idx, 'field': 'phone', 'value': row['phone'],
'error': 'Invalid phone format'}
for idx, row in invalid_phones.iterrows()
])
# Validazione date (assumendo una colonna 'date')
if 'date' in df.columns:
df['date'] = pd.to_datetime(df['date'], errors='coerce')
invalid_dates = df[df['date'].isnull() & df['date'].notna()]
if not invalid_dates.empty:
validations.extend([
{'row_id': idx, 'field': 'date', 'value': row['date'],
'error': 'Invalid date format'}
for idx, row in invalid_dates.iterrows()
])
# Creazione del report delle violazioni
violations_df = pd.DataFrame(validations)
# Aggiunta di statistiche aggregate
if not violations_df.empty:
print("\nViolation Statistics:")
print(f"Total violations: {len(violations_df)}")
print("\nViolations by field:")
print(violations_df['field'].value_counts())
else:
print("No violations found.")
return violations_df
# Esempio di utilizzo
if __name__ == "__main__":
# Creiamo un DataFrame di esempio con alcuni errori
data = {
'age': [25, 150, 30, -5],
'email': ['valid@email.com', 'invalid.email', 'another@valid.com', 'missing@.com'],
'phone': ['+1234567890', '123', '+441234567890', 'abc123'],
'date': ['2024-01-01', 'invalid_date', '2024-13-01', '2024-01-01']
}
df = pd.DataFrame(data)
violations = validate_data_accuracy(df)
# Output esempio:
# Violation Statistics:
# Total violations: 6
#
# Violations by field:
# age 2
# email 2
# phone 2
# Name: count, dtype: int642. Completezza: Oltre l’Assenza di Valori Mancanti
La completezza dei dati va ben oltre la semplice presenza o assenza di valori nulli. Un dataset veramente completo deve rappresentare l’intero spettro del fenomeno che stiamo cercando di modellare. Nel contesto dell’AI, dati incompleti possono portare a bias significativi nel modello, limitando la sua capacità di generalizzare correttamente.
Per monitorare la completezza, dobbiamo considerare sia la presenza di tutti i campi necessari sia la rappresentatività del dataset. Ecco come possiamo implementare un controllo base.
import pandas as pd
import numpy as np
from typing import Dict, Any
from scipy import stats
def check_completeness(df: pd.DataFrame) -> Dict[str, Any]:
"""
Analizza la completezza di un DataFrame, includendo:
- Ratio di completezza generale e per colonna
- Analisi della distribuzione dei dati
- Pattern di valori mancanti
- Statistiche di base per colonne numeriche
Args:
df: DataFrame da analizzare
Returns:
Dictionary contenente le metriche di completezza e distribuzione
"""
# 1. Analisi generale della completezza
total_cells = df.size
missing_cells = df.isnull().sum().sum()
completeness_ratio = 1 - (missing_cells / total_cells)
# 2. Analisi per colonna
column_completeness = (1 - (df.isnull().sum() / len(df))).round(4)
# 3. Pattern di valori mancanti
missing_pattern = pd.DataFrame({
'missing_count': df.isnull().sum(),
'missing_percentage': (df.isnull().sum() / len(df) * 100).round(2),
'unique_values': df.nunique(),
})
# 4. Analisi della distribuzione per colonne numeriche
distribution_metrics = {}
numeric_cols = df.select_dtypes(include=[np.number]).columns
for col in numeric_cols:
if df[col].notna().any(): # Skip if all values are NA
data = df[col].dropna()
distribution_metrics[col] = {
'mean': data.mean(),
'median': data.median(),
'std': data.std(),
'skewness': data.skew(),
'kurtosis': data.kurtosis(),
'iqr': data.quantile(0.75) - data.quantile(0.25),
'range': data.max() - data.min(),
'zeros_percentage': (data == 0).mean() * 100,
}
# 5. Analisi delle colonne categoriche
categorical_cols = df.select_dtypes(include=['object', 'category']).columns
categorical_metrics = {}
for col in categorical_cols:
if df[col].notna().any():
value_counts = df[col].value_counts()
categorical_metrics[col] = {
'unique_values': len(value_counts),
'most_common': value_counts.index[0] if not value_counts.empty else None,
'most_common_count': value_counts.iloc[0] if not value_counts.empty else 0,
'least_common': value_counts.index[-1] if not value_counts.empty else None,
'least_common_count': value_counts.iloc[-1] if not value_counts.empty else 0,
}
return {
'overall_completeness': {
'completeness_ratio': completeness_ratio,
'total_missing_percentage': (missing_cells / total_cells) * 100,
'total_cells': total_cells,
'missing_cells': missing_cells
},
'column_completeness': column_completeness.to_dict(),
'missing_patterns': missing_pattern.to_dict(),
'distribution_metrics': distribution_metrics,
'categorical_metrics': categorical_metrics
}
# Esempio di utilizzo
if __name__ == "__main__":
# Creiamo un DataFrame di esempio con diversi tipi di dati e valori mancanti
np.random.seed(42)
data = {
'age': np.random.normal(35, 10, 1000), # Distribuzione normale
'income': np.random.lognormal(10, 1, 1000), # Distribuzione log-normale
'category': np.random.choice(['A', 'B', 'C', None], 1000), # Categorica con NA
'score': np.random.uniform(0, 100, 1000), # Distribuzione uniforme
}
# Introduciamo alcuni valori mancanti
df = pd.DataFrame(data)
df.loc[np.random.choice(df.index, 100), 'age'] = np.nan
df.loc[np.random.choice(df.index, 50), 'income'] = np.nan
# Eseguiamo l'analisi
completeness_report = check_completeness(df)
# Stampiamo un report formattato
print("\n=== Completeness Analysis Report ===")
print(f"\nOverall Completeness: {completeness_report['overall_completeness']['completeness_ratio']:.2%}")
print(f"Total Missing Values: {completeness_report['overall_completeness']['missing_cells']} "
f"({completeness_report['overall_completeness']['total_missing_percentage']:.2f}%)")
print("\nCompleteness by Column:")
for col, ratio in completeness_report['column_completeness'].items():
print(f"{col}: {ratio:.2%}")
print("\nDistribution Metrics (Numeric Columns):")
for col, metrics in completeness_report['distribution_metrics'].items():
print(f"\n{col}:")
for metric, value in metrics.items():
print(f" {metric}: {value:.2f}")
print("\nCategorical Metrics:")
for col, metrics in completeness_report['categorical_metrics'].items():
print(f"\n{col}:")
for metric, value in metrics.items():
print(f" {metric}: {value}")3. Attualità: Il Valore del Tempo nei Dati
Nell’era dei sistemi real-time e degli agenti AI autonomi, l’attualità dei dati diventa un fattore critico. Un dato accurato ma obsoleto può essere altrettanto dannoso quanto un dato inaccurato.
L’attualità deve essere valutata in relazione al contesto specifico: alcuni dati potrebbero rimanere validi per anni, altri potrebbero diventare obsoleti in poche ore.
4. Consistenza: L’Armonia tra i Sistemi
Quando parliamo di consistenza dei dati, dobbiamo considerare quattro dimensioni fondamentali, ognuna delle quali gioca un ruolo cruciale nella qualità complessiva dei dati che alimentano i nostri sistemi AI.
La Consistenza Strutturale: Il Fondamento dell’Ordine
La consistenza strutturale rappresenta il livello più basilare ma fondamentale della qualità dei dati. Immaginate di ricevere dati da diverse filiali di un’azienda: ogni filiale potrebbe utilizzare il proprio formato per registrare le date. Alcune potrebbero usare il formato europeo (DD/MM/YYYY), altre quello americano (MM/DD/YYYY), creando un potenziale caos nell’analisi dei dati.
Questo tipo di inconsistenza non si limita solo alle date. Un problema frequente riguarda i numeri decimali: mentre alcuni sistemi utilizzano il punto come separatore decimale, altri utilizzano la virgola. Pensate a un sistema di analisi finanziaria che deve aggregare dati da diverse fonti: una piccola differenza nel formato può portare a errori significativi nei calcoli.
Un altro aspetto critico è l’encoding dei caratteri. In un mondo globalizzato, dove i dati possono contenere caratteri di alfabeti diversi, un encoding non uniforme può trasformare nomi e descrizioni in sequenze illeggibili di simboli.
La Consistenza Semantica: Parlare la Stessa Lingua
La consistenza semantica va oltre la semplice struttura dei dati, entrando nel territorio del loro significato. Un esempio classico è la definizione di “cliente attivo”: per il reparto vendite potrebbe essere un cliente che ha effettuato un acquisto negli ultimi 3 mesi, mentre per il reparto marketing potrebbe essere chiunque abbia interagito con l’azienda nell’ultimo anno.
La Consistenza Referenziale: Mantenere le Connessioni
La consistenza referenziale è fondamentale in un mondo dove i dati sono interconnessi. Pensiamo a un sistema e-commerce: ogni ordine deve essere associato a un cliente valido. Se un cliente viene eliminato dal database, cosa succede ai suoi ordini storici? Le chiavi esterne orfane possono creare buchi nella nostra comprensione dei dati.
La duplicazione di entità è un altro problema insidioso. Se lo stesso cliente viene registrato due volte con leggere variazioni nel nome, il sistema potrebbe non riconoscere che si tratta della stessa persona, portando a analisi frammentate e decisioni basate su dati incompleti.
La Consistenza Temporale: La Quarta Dimensione dei Dati
La dimensione temporale aggiunge un ulteriore livello di complessità alla gestione dei dati. Prendiamo l’esempio di un sistema di prezzi: quando un prezzo viene aggiornato, come gestiamo gli ordini storici? Il prezzo mostrato dovrebbe essere quello al momento dell’ordine o quello corrente?
L’implementazione di questi livelli di consistenza dipende dal dominio dei dati ma è necessario per assicurare una buona qualità dei dati.
5. Unicità: L’Importanza dei Dati Unici
La presenza di duplicati nei dati può distorcere significativamente le analisi e l’apprendimento dei modelli AI. La deduplicazione non è sempre un processo semplice: i duplicati possono essere esatti o approssimativi, e la decisione su cosa costituisce un duplicato dipende spesso dal contesto specifico.
L’Impatto dei Duplicati sui Sistemi AI
Immaginate di addestrare un modello di machine learning per prevedere il comportamento d’acquisto dei clienti. La presenza di duplicati può causare diverse distorsioni:
- Sovrarappresentazione
- Se un cliente appare più volte nel dataset, il modello potrebbe dare un peso eccessivo ai suoi pattern comportamentali
- Per esempio, se “Mario Rossi” appare tre volte con piccole variazioni nel nome, il suo comportamento d’acquisto avrà un’influenza tripla sul modello
- Bias nelle Metriche
- Il calcolo del lifetime value dei clienti risulterebbe falsato
- Le metriche di engagement potrebbero essere sovrastimate o sottostimate
- I KPI aziendali potrebbero portare a decisioni strategiche errate
- Inefficienza Computazionale
- I duplicati consumano risorse di storage inutilmente
- Il tempo di elaborazione aumenta senza portare benefici reali
- La complessità dei modelli cresce artificialmente
6. Granularità e Rilevanza: Il Giusto Livello di Dettaglio
La granularità dei dati determina il livello di dettaglio disponibile per l’analisi e l’apprendimento. Un livello di granularità troppo alto può nascondere pattern importanti, mentre uno troppo basso può introdurre rumore nei dati e aumentare inutilmente la complessità computazionale.
La scelta della granularità appropriata dipende da vari fattori:
- Gli obiettivi specifici del progetto AI
- Le risorse computazionali disponibili
- I requisiti di tempo reale
- La natura del dominio applicativo
Per gestire efficacemente la granularità, è necessario implementare sistemi che permettano di aggregare e disaggregare i dati in modo flessibile.
Data quality best practices
La gestione della qualità dei dati richiede un approccio olistico che combini persone, processi e tecnologie. Vediamo come questi elementi si intrecciano per creare un ecosistema di dati affidabile e di alta qualità.

La governance
La governance dei dati rappresenta il punto di partenza per qualsiasi iniziativa di qualità dei dati. Non si tratta semplicemente di stabilire regole, ma di creare una vera e propria cultura della qualità dei dati all’interno dell’organizzazione.
Questa cultura inizia con la chiara definizione di ruoli e responsabilità: chi è il “proprietario” di determinati dati? Chi ha l’autorità di modificarli? Chi ne monitora la qualità? Ad esempio, in un’organizzazione tipica, potremmo avere data steward responsabili della qualità quotidiana dei dati, analisti che ne verificano l’accuratezza e data engineer che implementano i processi di validazione.
Gli standard di gestione devono essere chiari ma flessibili, adattandosi alle diverse esigenze dei vari reparti pur mantenendo una coerenza di base. La sicurezza e la compliance non sono optional: in un’epoca di normative sempre più stringenti come il GDPR, ogni aspetto della gestione dei dati deve essere documentato e conforme alle leggi vigenti.
L’importanza della formazione
La qualità dei dati non è responsabilità esclusiva del reparto IT o del team di data science. Ogni persona che inserisce, modifica o utilizza i dati deve essere formata adeguatamente. Un programma di training efficace non si limita a insegnare l’uso degli strumenti, ma crea consapevolezza sull’importanza della qualità dei dati.
La documentazione
La documentazione accurata è come la memoria di un’organizzazione. Non si tratta solo di scrivere procedure, ma di mantenere una traccia viva e aggiornata di come i dati vengono gestiti. Ogni fonte di dati deve essere documentata: da dove provengono i dati? Come vengono trasformati? Quali sono le assunzioni alla base delle nostre analisi?
Il ciclo di feedback
Un sistema di feedback efficace è cruciale per il miglioramento continuo. Quando viene identificato un errore nei dati, non basta correggerlo: bisogna capire perché si è verificato e come prevenirlo in futuro. Gli utenti devono poter segnalare facilmente problemi o anomalie, e queste segnalazioni devono tradursi in azioni concrete di miglioramento.
Il feedback non riguarda solo gli errori: suggerimenti per migliorare i processi, idee per nuove validazioni, osservazioni su pattern ricorrenti sono tutti elementi preziosi per migliorare la qualità dei dati nel tempo.
Monitoraggio
Il monitoraggio continuo delle metriche di qualità dei dati è essenziale per mantenere alti standard nel tempo. Queste metriche devono essere:
- Rilevanti per il business
- Facili da comprendere
- Azionabili
- Tracciabili nel tempo
Un dashboard di monitoraggio efficace potrebbe mostrare:
- Trend della completezza dei dati
- Tasso di errori nel tempo
- Velocità di risoluzione dei problemi
- Impatto delle iniziative di miglioramento
L’importante è non limitarsi a raccogliere metriche, ma utilizzarle attivamente per guidare il miglioramento continuo della qualità dei dati.
Verso un futuro guidato dalla qualità dei dati
Come abbiamo visto quindi, nel percorso verso l’adozione dell’intelligenza artificiale, molte aziende si concentrano principalmente sugli algoritmi e sui modelli. Tuttavia, l’esperienza ci insegna che la vera chiave del successo risiede nella gestione della qualità dei dati che alimentano questi sistemi. Non si tratta semplicemente di una necessità tecnica: la qualità dei dati è diventata un imperativo strategico che può determinare il successo o il fallimento delle iniziative di AI.
Mentre ci muoviamo verso un futuro dominato dagli agenti AI – sistemi sempre più autonomi e sofisticati – la qualità dei dati assume un ruolo ancora più critico. Un agente AI, per quanto avanzato, non può compensare le carenze nei dati di base. È come costruire un grattacielo: per quanto sofisticata sia l’architettura, senza fondamenta solide l’intera struttura è a rischio.
Abbiamo visto diversi aspetti a cui prestare attenzione, ma forse, l’aspetto più sfidante, ma anche il più importante, è la creazione di una vera cultura della qualità dei dati.
Questa cultura deve permeare ogni livello dell’organizzazione, dal CEO all’addetto all’inserimento dati. Ognuno deve comprendere l’importanza del proprio ruolo nella catena del valore dei dati.
Esistono numerosi strumenti da poter utilizzare. Ad esempio, sul fronte della governance ad esempio, il framework DAMA DMBOK e lo standard ISO/IEC 25012 offrono linee guida complete per strutturare i processi di gestione dei dati. Questi framework non sono semplici checklist da seguire, ma veri e propri modelli di che possono guidare l’evoluzione della governance dei dati nel tempo.
Il viaggio verso l’eccellenza nella qualità dei dati è un maratona, non uno sprint. Richiede impegno costante, risorse dedicate e, soprattutto, una visione chiara del valore che porta all’organizzazione. Ma i benefici sono tangibili: sistemi AI più affidabili, decisioni più accurate, maggiore efficienza operativa e, in ultima analisi, un vero vantaggio competitivo nel mercato sempre più data-driven di oggi.
La qualità dei dati non è un costo da sostenere, ma un investimento nel futuro della vostra organizzazione. E come ogni buon investimento, se fatto con saggezza e costanza, porta rendimenti che superano di gran lunga l’impegno iniziale.
Hai bisogno di supporto?
Se stai affrontando sfide nella gestione della qualità dei dati nella tua organizzazione o vuoi approfondire alcuni degli aspetti trattati in questo articolo, sarò lieto di aiutarti.
Come esperto di data engineering e architetto software, posso aiutarti a:
- Valutare lo stato attuale della qualità dei dati nella tua organizzazione
- Definire una strategia personalizzata per il miglioramento
- Implementare soluzioni tecniche appropriate
- Formare il tuo team sulle best practice
Contattami per una consulenza
Alla prossima informazione!
fonti: https://www.cio.com/article/3610263/why-data-quality-drives-ai-success.html